
Demystifying URL paths

Look, I know that URL paths are not the sexiest sounding thing ever. But if I have one goal with this article, it is to convince you that URL paths are, in fact, sexy af. And quite simple.
Once you understand them, you can’t help but stand in awe at your newfound power to create powerful and elegant navigation systems for your app, whether it’s a multi page application (MPA) single page application (SPA) or some hybrid of the two.
Let’s start with some fundamentals

The URL is a place where we can store data, just like any other container (like groups and custom states). However, due to the fact that the URL is essentially just one long text string, we have speak to it in text. But that’s okay, text is all we need.
Within the URL we can store data either in the path (as segments, more on those in a moment), or in parameters. These come after your root domain (yourapp.com, or yourapp.com/version-test if you’re in development mode).

Note, we can also store data as anchors which scrolls the user to a particular element on the page (useful for blog posts, documentation etc). We’re not discussing them here, but see Bubble’s documentation for more info.
Paths are easy to read, favourable by SEO, and have a natural hierarchy to them, like folders or files nested inside of folders. They’re suitable for storing information about what the user should be seeing (i.e. the view/page). The order in which they appear is important, and having too many can make your page navigation overly confusing.
Parameters don’t have a natural hierarchy: each one is a standalone nugget of information, made up of a key (it’s label) and a value (the information). This means you can add an arbitrary number of them in any order, which makes them are suitable for storing information (variables) that the page needs to operate.
In the example below from Mailerlite, the path, subscribers, is telling us what page or view we’re on, while the parameter, status, is being used to filter a table on the page.

If I use a dropdown on the page to change the filter from active…
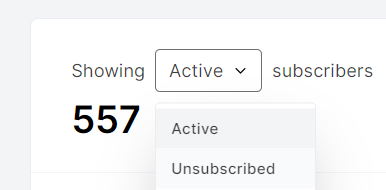
to unsubscribed….

… then the URL parameter changes accordingly.

Alas, parameters are a conversation for another day.
When it comes to paths, we store these as segments; individual pieces of information separated by /. So a path can be made up of a list of segments.

In the example above, we’re on the page p, and then within p, looking at a particular article, retrieved using demystifying-url-paths.
Alright, but how do we actually deal with these path segments in Bubble?
URL paths in Bubble
In order to retrieve any data from the URL, we use get data from page URL.
When we do this, we get several options.

If we choose path segments as list, this returns a list of texts, where each item in the list is a path segment.
So in the case of blog.mattneary.co/p/demystifying-url-paths, this list would be:
p
demystifying-url-paths
Since, unlike parameters, we can’t identify a path by a key value (a label for that data, basically), in order to access a particular segment, we must grab it by it’s position (it’s index) in the list.


As you can see above, the first path segment is always the page name. It’s populated for us simply by virtue of being on a particular page. Each segment which follows we must push into the URL ourselves (we’ll get to how to do that shortly).
What about grabbing just the ‘path‘?
Now, as an extra complication, Bubble actually gives us the option to grab, not the page segments, but just the path.

You might expect this to be the first segment in the URL, i.e., the page name (setting, in the example above). But, it’s not.
If you grab the path from the page URL, this is the same as path segment #2.
To grab the page name, you either grab path segment #1, or use a different expression: current page name; just note that you can only access this expression from within a reusable element.
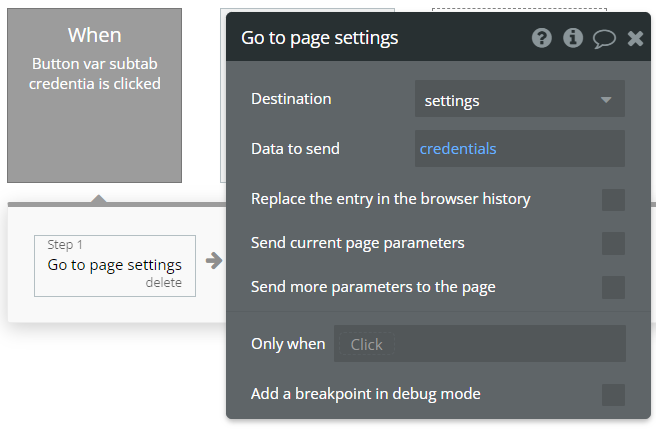
Populating the URL with path segments
Finally, to actually populate the URL with such paths, we use the go to page action, sending the URL paths in the data to send input.

Having elements react to changes in the path
We’ve already seen how we can extract URL paths using get data from page URL. From here, it’s simply a matter of constructing expressions that utilize them.
Conditional logic
To add conditional formatting to the buttons, we can simply extract the path (or path segment number x) and compare it to some other value.


In the above example, I’m manually typing out “profile“, but what you really should be doing to avoid duplication is storing value in a single place that you can then reference everywhere (like in a group acting as a variable, or in an option set). I’ll elaborate on this kind of setup in a separate post.
The same principle as above can be used to display the content on the page which corresponds to the current view. And thus, within-page navigation is born!

Extracting URL paths as data
Now, with the setup above, we’re extracting the url path as text. But Bubble also lets us pull it out as any data type.

Yet if, at the end of the day, all we have is text in a URL, how does this work? How do we go from text, to say, a product?
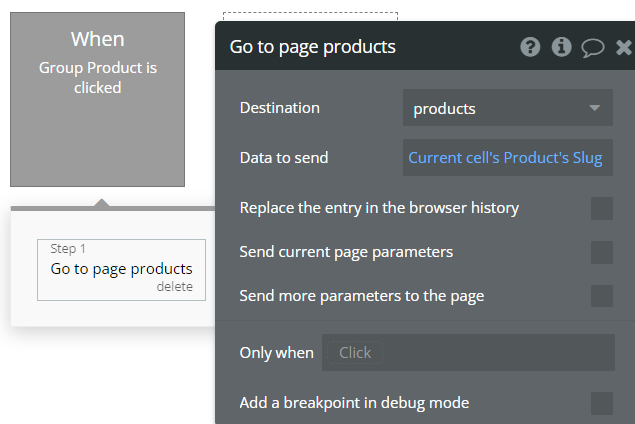
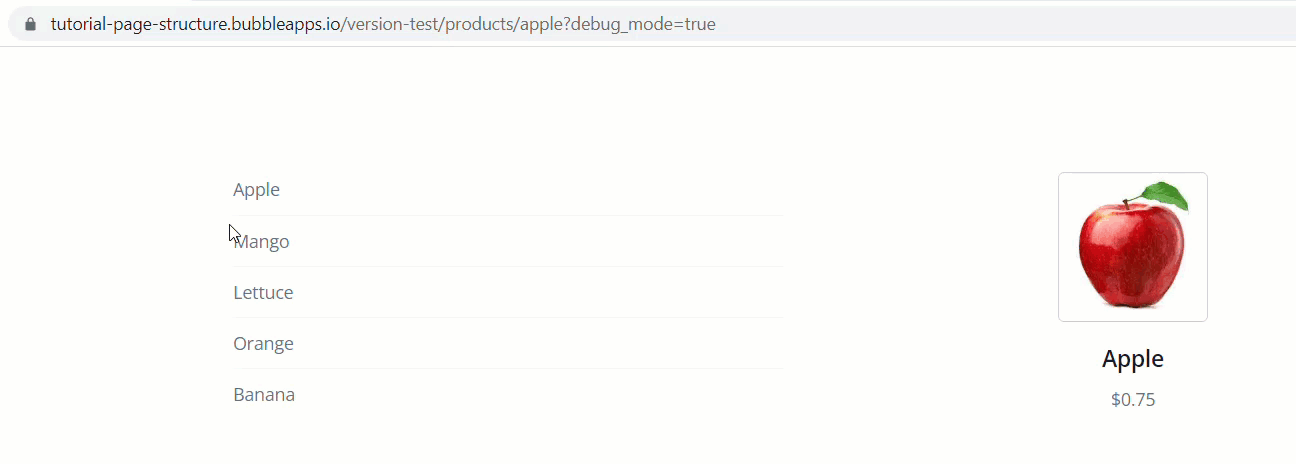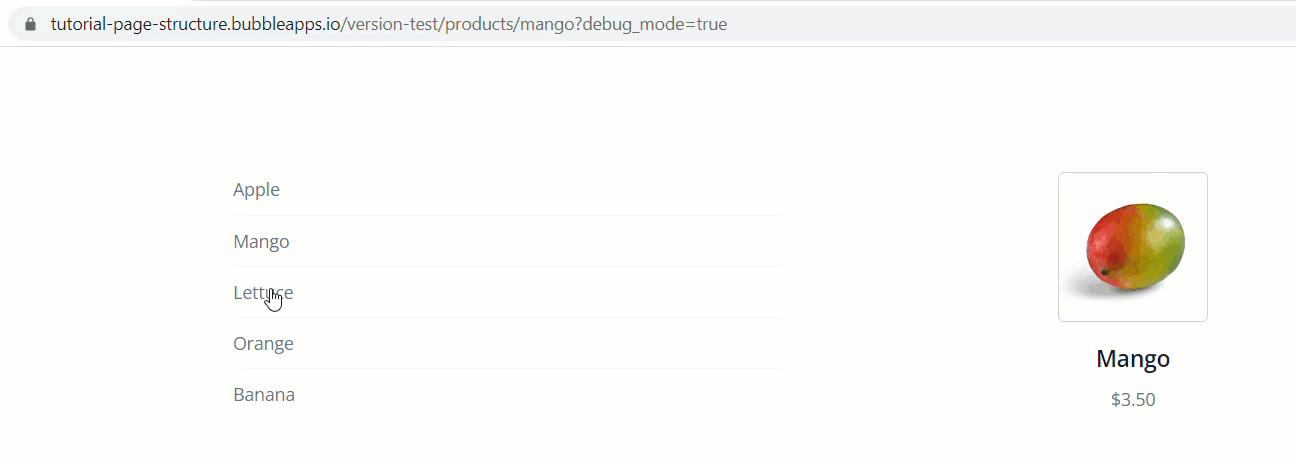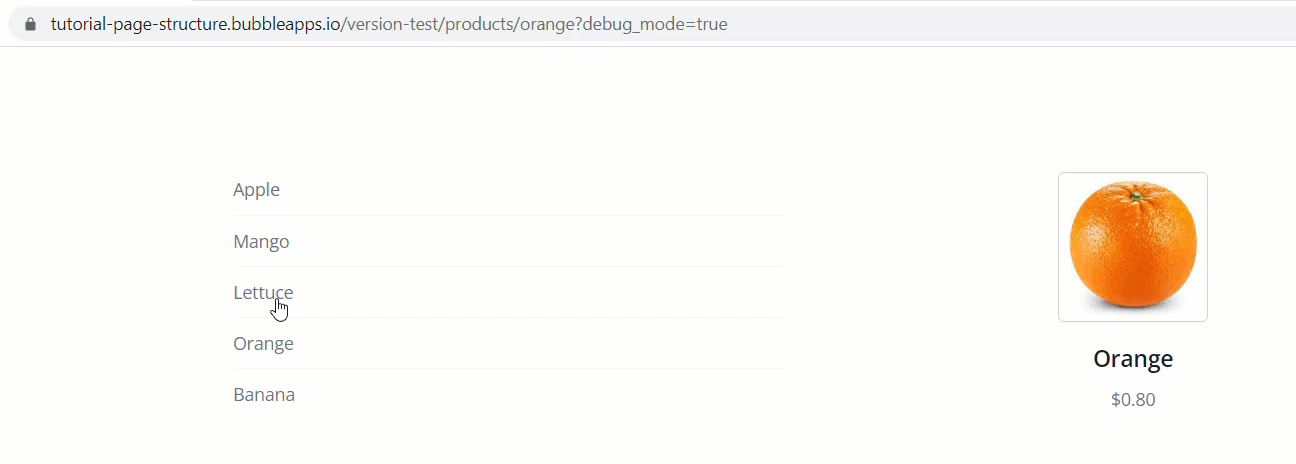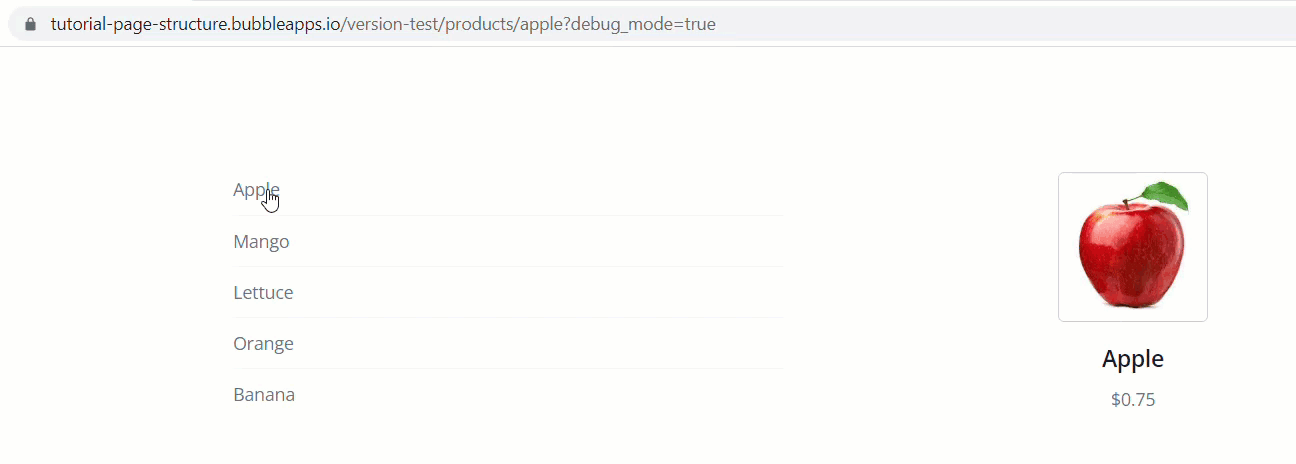
To demonstrate, let’s look at the following products page. We’ve got a repeating group of food products. Clicking one of the products pushes that product’s unique ID into the URL

So the path segments in text form at this point are:
products
[some-product ID] (i.e. 24234234233x23453242324
If we retrieve the path segments as a list of products, not texts, what happens?



As you can see, we’re retrieving two segments from the URL here (products and [some-ID], but only one of them is being recognized as a product.
For the segment that Bubble does recognize as a product, it automatically retrieves that product from the database, using it’s unique ID to locate it1. It then returns that product in place of the path segment. Since only one of those segments actually is a product ID, only one product is being returned.
If we were to hack the URL, as it were, and add a third path segment consisting of a product ID, then two products would be returned.


This means that you can pull, as it were, entire objects from the database from the URL and use them to populate containers on the page.


But, you might say, I thought the whole point of URL paths was that they looked pretty? Now you’re telling me I gotta look at this ugly unique ID?
Not if you don’t want to.
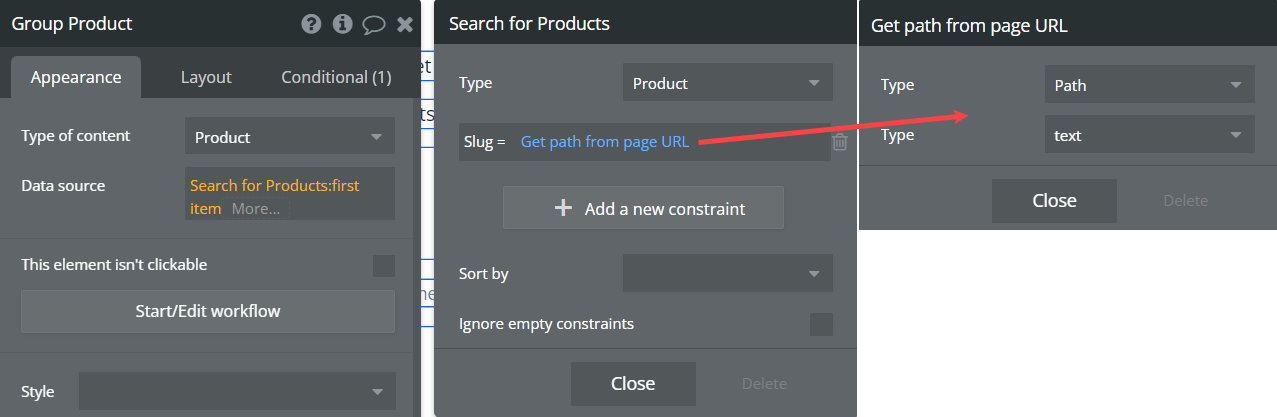
Rather than pulling objects in using the technique above, the approach you’ll more likely want to do is push an objects slug into the URL (cause they look pretty) and then simply do a search for that object, using the path slug value as the search constraint.
So this is the fundamentals of URL paths - but we’re really just scratching the surface on what they can do. By stacking different paths, we can build some quite powerful and intuitive app navigation structures. Stay tuned for more guides on how those work!
If you’re still hungry for Bubble educational content:
Check me out on Youtube, where I frequently publish free Bubble tutorials.
Or, if you want a comprehensive, zero-to hero introduction to Bubble, my flagship course, Think it, Build it, is for you. Enrolment opening end of October!
This works the same for identifying options sets, only for those, Bubble uses the display value to identify it.